Project Showcase
Some of my projects are industrial-sponsored and therefore being partially or fully under NDA. Belows are brief descriptions of my major projects which are also public.
- Statistical Significance of Features in Neural Networks
- Low-Resource Framework for LLM Content Detection, 2023-2024
- Deep Reinforcement Learning for 5G Network Slicing, 2022
- AI Tracking of Heart Rates during Physical Exercises, 2022
- Deep Reinforcement Learning for Quantum Entanglement Routing, 2021
- Analysis of Students’ Concentration in Online Learning, 2021
- Real-time Workout Assistant, 2021
- One-class Attention Architecture for Anomaly Detection in Manufacturing, 2020
- Environment Noise Removal for Speech Processing, 2020
- Deep Embedding Kernel, 2019
- Recurrent KNN for Predicting Daily Stock Price Direction, 2018
- Graph-based Multivariate Sales Forecasting, 2017
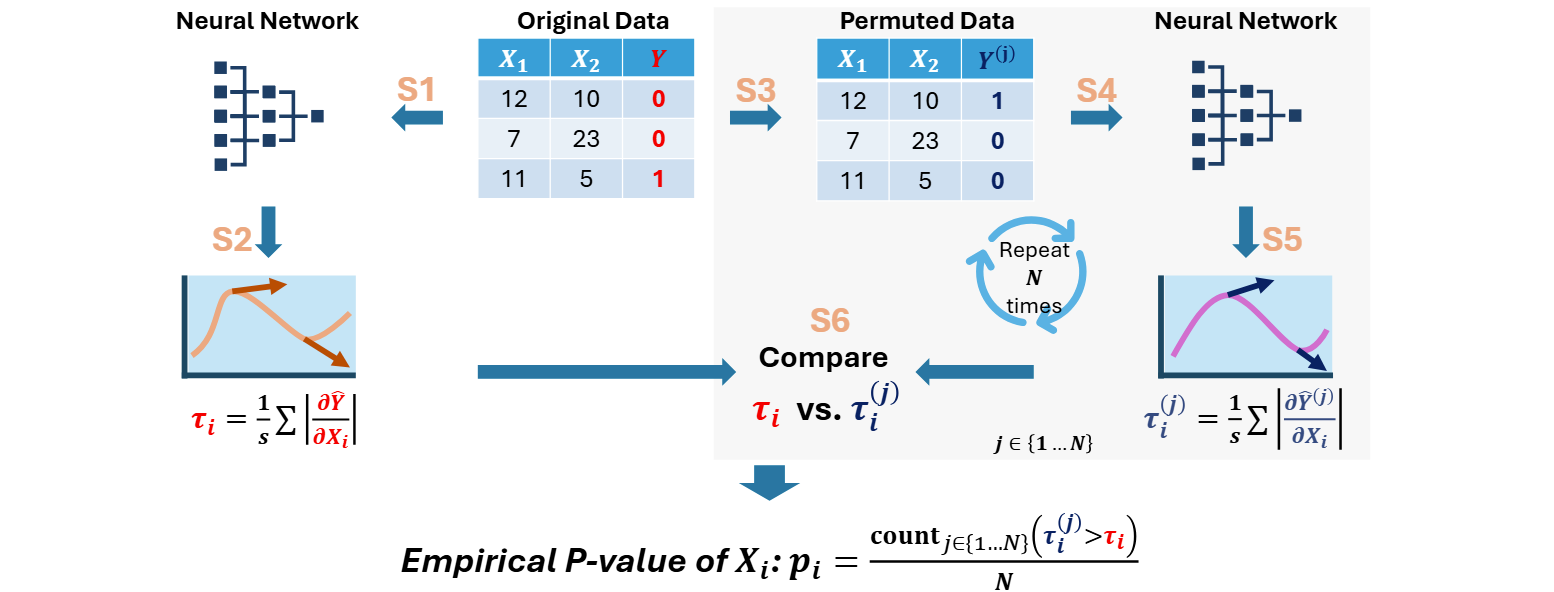
Statistical Importance of Features in Neural Networks
This work was presented in ICMLA 2024.
Motivation: A lot of methods exist for determining the importance of features in neural networks. However, they only generate one importance measurement for each feature which is useful for cross comparison but not suitable for assessing if features are truly significant or not. Furthermore, many approaches assume independence among the features which is rarely the case in practice.
Product: We developed a target permutation test to further generate a measurement of statistical significance for the features.
Technology: First, we train a neural network on the given data and compute the importance of each feature using their absolute partial gradient with respect to the network's output. Then, for a number of times, we shuffle the true output in data, train a new neural network on the shuffled data and record the new importances in each case. Finally, the statistical significance of a feature is the chance that the neural network views it as more important in the randomly shuffled data than in the true data.
Result: Our permutation test can effectively detect statistically significant features regardless of its association to the target or other features. Using the statistical significance, we can reduce up to 60% of features while maintaining or even improving the performance of models.
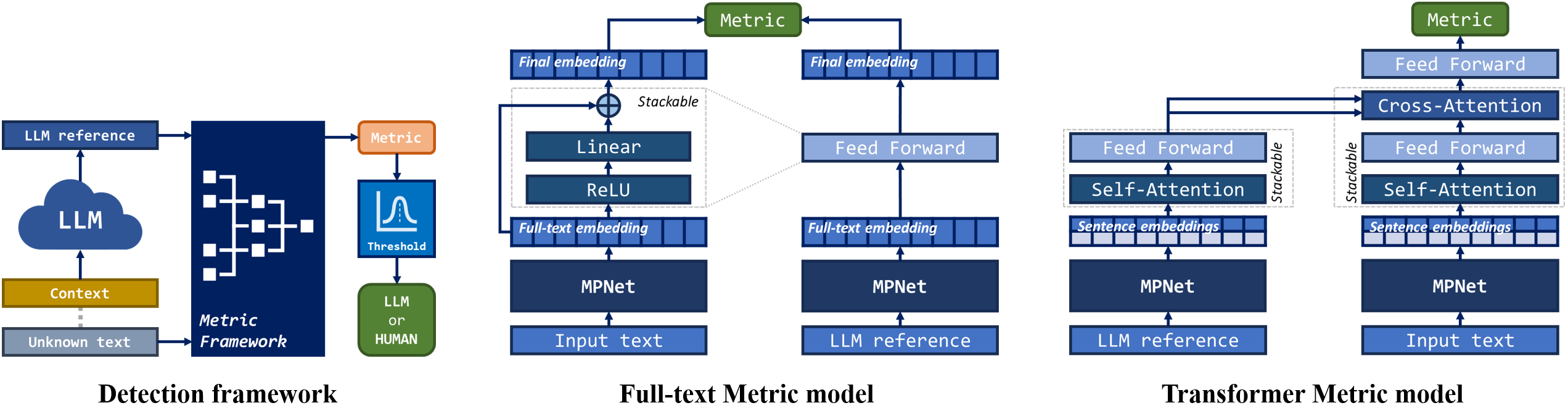
Low-Resource Framework for LLM Content Detection
This work was presented in ICLR 2024 and accepted at ACM Transactions on Management Information Systems.
Motivation: Current Large Language Models (LLMs) are able to generate texts that are seemingly indistinguishable from those written by human experts. While offering great opportunities, such technologies also pose new challenges in education, science, information security, and many other areas.
Product: We developed a new paradigm of metric-based detection for LLM contents that is able to balance among computational costs, accessibility, and performances. Additionally, from over 500,000 text pieces, we processed, developed and will publish five datasets totalling 95,000+ prompts and responses from human and GPT-3.5 TURBO or GPT-4 TURBO for benchmarking.
Technology: The detection is performed through utilizing a metric framework to evaluate the similarity between a given text to an equivalent example generated by LLMs and determine the former's origination.
Result: our framework maintains 90-150% F1 scores of a finetuned RoBERTa, significantly outperformed LLaMA 3, Mistral 0.3, and Ghostbuster while only spends 20-60% of times in training and inference across experiment settings.
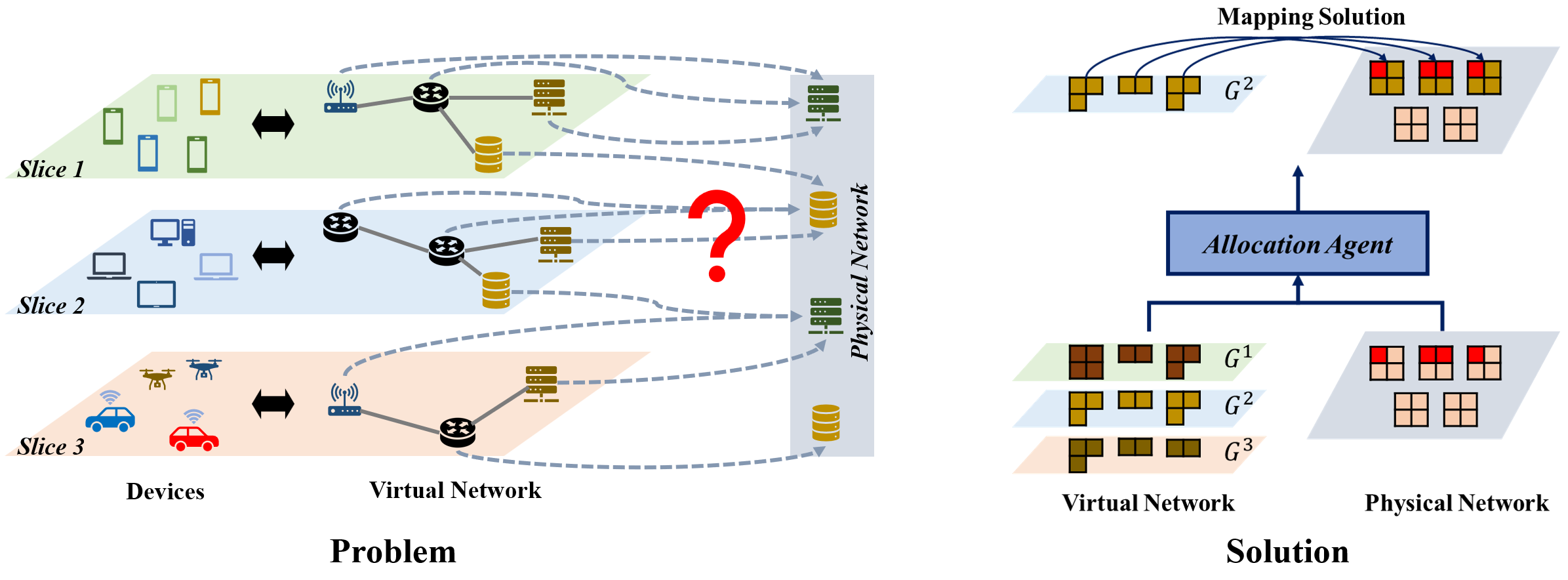
Deep Reinforcement Learning for 5G Network Slicing
This work won best paper in DroneCon 2022, MobiCom 2022.
Motivation: 5G radio access network (RAN) slicing aims to logically split a physical network infrastructure into programmable virtual slices, each of which serves a separate logical mobile network, e.g., for a specific service. A RAN slice consists of various virtual network functions (VNFs) that serve purposes such as storage, routing, processing, etc. A key challenge in building a robust RAN slicing is, therefore, to design a RAN slicing scheme that can utilize information such as resource availability in physical networks as well as the interdependent relationships among slices to map VNFs to physical nodes.
Product: we implemented a deep reinforcement learning RAN slicing schemet, namely Deep Allocation Agent (DAA), that aims to accommodate maximum numbers of slices within a given request set.
Technology: DAA utilizes an empirically designed deep neural network that observes the current states of the substrate network and the requested slices to schedule the slices of which VNFs. The selected VNF is then mapped to substrate nodes using an optimization algorithm. DAA is trained to maximize the number of accommodated slices in the given set.
Result: DAA maintains a rate of successful slices above 80% in a resource-limited physical networks, and about 60% in extreme conditions. DAA is also fast to converge and has polynomial time complexities with respect to changes in the substrate network or demands.
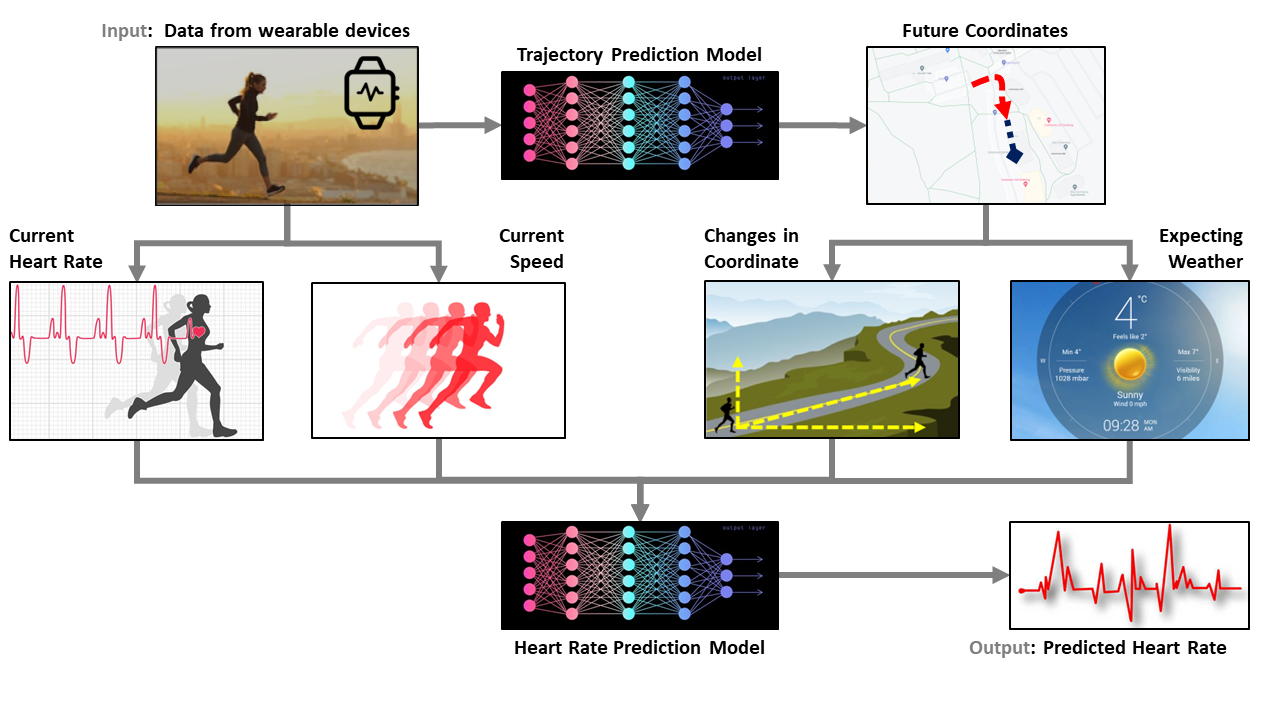
AI Tracking of Heart Rates during Physical Exercises
This is a capstone project performed by two student teams that I mentored in Fall 2022.
Motivation: Heart rate monitoring provides numerous benefits. For example, a person’s heart rate can be tracked during physical exercise so that they can be warned when it gets too high. The development of wearable devices has made heart rate monitoring become much easier than before. However, data analytical models that are used for this task are still relatively limited.
Product: We developed a deep learning method to track and predict the heart rate of a person in immediate future (i.e., the next few seconds to minutes) during exercising.
Technology: Utilizing the GPS information, we first retrieve information like weather (temperature, humidity, etc.) and geography (longitude, latitude, altitude) to is incorporated into the model data. Then, we empirically design Attention/RNN/CNN models to predict the next-second heart rate
Result: Our technology can predict next-second heart rates within an error margin of 7 beats-per-minute.
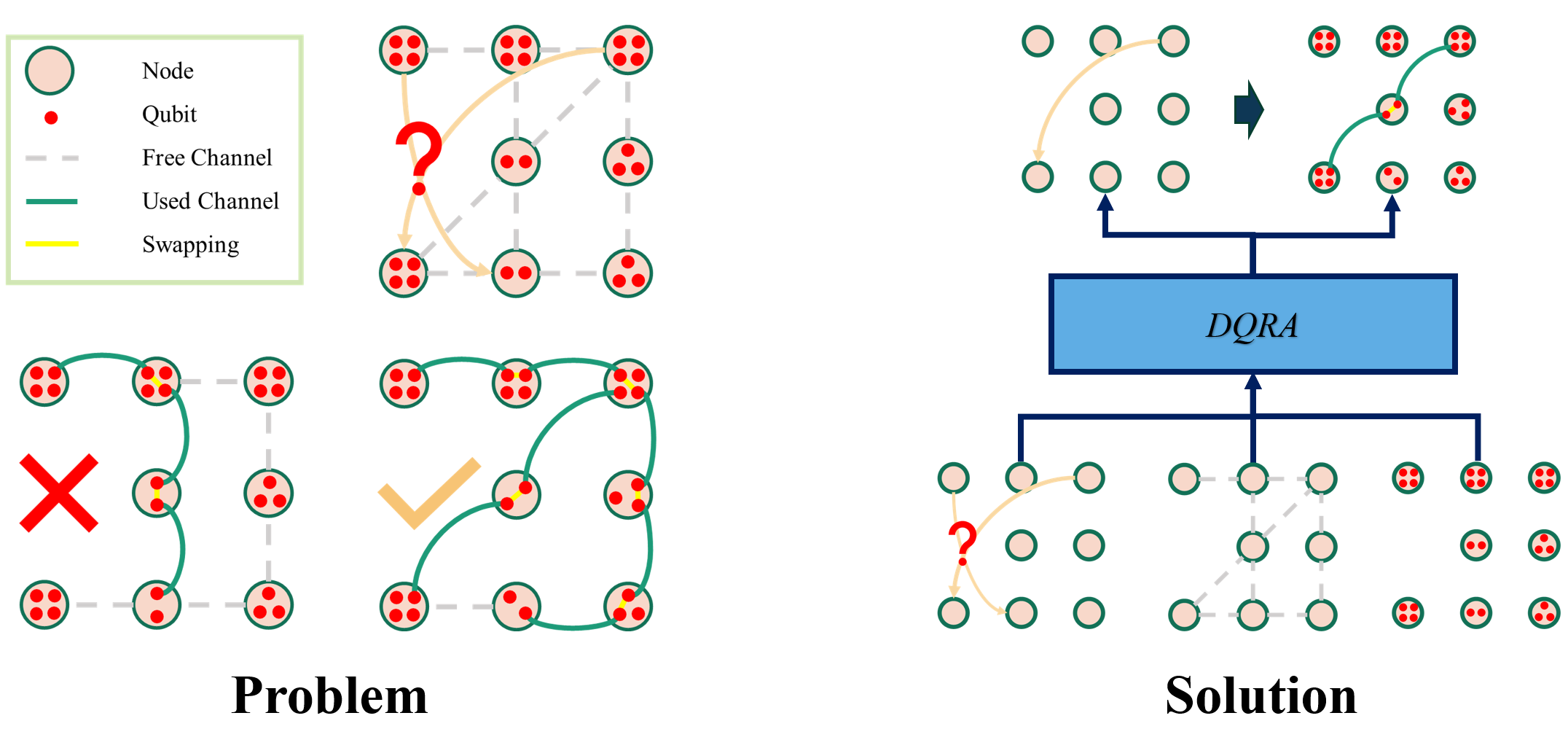
Deep Reinforcement Learning for Quantum Entanglement Routing
This work was presented in Infocom 2021 and published in IEEE Transactions on Quantum Engineering.
Motivation: Quantum entanglement is the phenomenon in which two particles become intercorrelated -- if we know the state of one particle, we also know that of the other. This is the key to transfer data through a quantum network. More specifically, if we can entangle particles, or qubits, in a source site with the ones in the destination, data could be transfer through those quantum connections. However, qubits too far from each other cannot entangle. Instead, they need to entangle with intermediate ones, then those entanglements can be swapped to form the source-destination interconnection. Therefore, in a quantum network, an important task when deliver data from a source to a destination is to determine which nodes in the network has available qubits to perform all the necessary entanglements. This task is called quantum entanglement routing.
Product: we develop a novel routing model, Deep Quantum Routing Agent (DQRA), for quantum networks that employs deep reinforcement learning to construct paths for source-destination pairs within a time window .
Technology: DQRA utilizes an empirically designed deep neural network that observes the current network states (topology and qubic capacity) as well as all source-destination demands to schedule the data delivery. Each source-destination pair is then routed by a qubit-preserved shortest path algorithm.
Result: DQRA maintains a rate of successfully routed requests at above 80% in a qubit-limited grid network, and approximately 60% in extreme conditions. Furthermore, the model complexity and the computational time of DQRA are polynomial in terms of the sizes of the quantum networks.
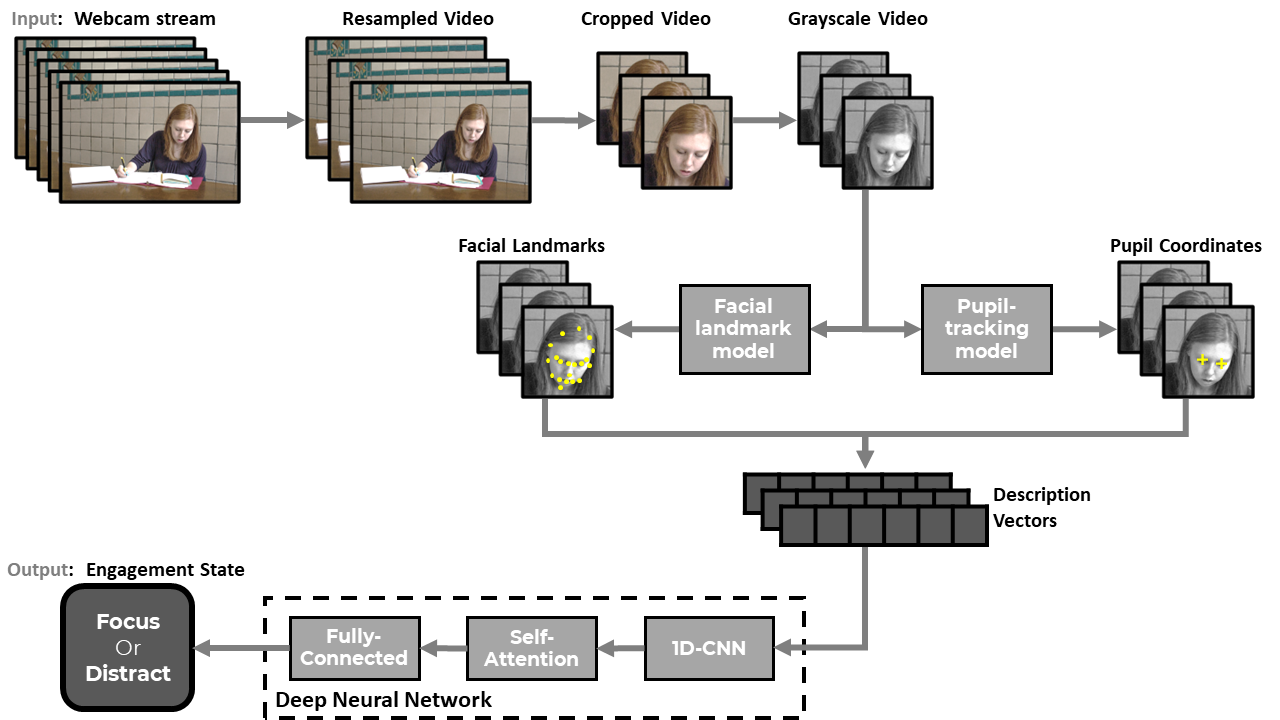
Analysis of Students’ Concentration in Online Learning
This work had three components spanning three semester with multiple Capstone teams. The final product was published in IEEE Big Data 2021 (acceptance rate 19.9%).
Motivation: Tracking the concentration of students during online learning offers great benefits. For examples, distracted students can be suggested to do a brief exercise to refresh their brains; or the teacher can be notified when too many students have difficulties on concentration so the class could take a break.
Product: We develop an AI system to track students' concentration levels during online learning using facial data captured by webcam.
Technology: video data from webcam first undergoes a preprocessing pipeline of resampling, cropping, and converting to grayscale. The processed videos are then transformed into streams of facial landmarks and pupil coordinates. In terms of modeling, we utilize a deep neural network architecture of 1D Convolutional Neural Network and Self-Attention Neural Network.
Result: The framework reached over 91% accuracy in predicting if a student is focusing or being distracted which outperformed state-of-the-art facial models including VGG2 and Google FaceNet.
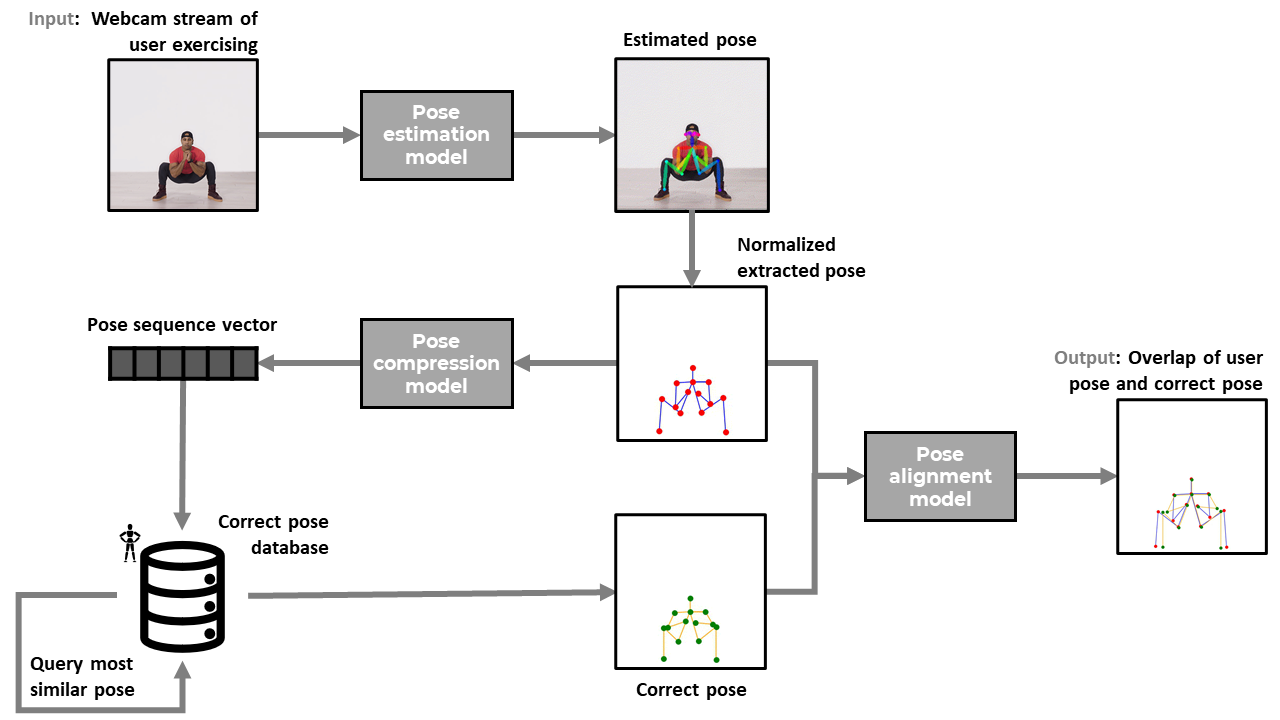
Real-time Workout Assistant
This work had three components spanning two semester with multiple Capstone teams. A component was published in IEEE Big Data 2020 (acceptant rate 17%), and another one won KSU C-Day Spring 2021.
Motivation: The COVID-19 pandemic has brought to the forefront the importance of promoting a healthy lifestyle. Chronic medical conditions including obesity, diabetes, heart disease, COPD, and kidney diseases, raise the risk of suffering a severe case of COVID-19. Therefore, in addition to containment and mitigation, we need to look at preventative measures such as identifying and promoting ways for individuals to improve their health, especially those who live in the areas that are the hardest hit by the pandemic.
Product: We develop a novel smart virtual exercise/rehabilitation assistant to assist people in physical exercises by learning and providing visual feedback to users during or after their training sessions.
Technology: We generate the visual feedback by overlaying the current user pose with a correct pose, e.g. a pose that is collected from a professional trainer or a physiatrist. The user can then observe which parts of their pose that are being performed incorrectly and how to fix them accordingly. We utilize multiple deep learning technologies to develop three models: 1) pose estimation model that transform videos into sequence of poses, 2) pose compression model that transform pose sequences into representation vectors for querying most similar poses, and 3) pose alignment model that match and overlay the two input poses.
Result: The alignment models are able to fix 70% misalignment between similar poses in different camera views and perspective.
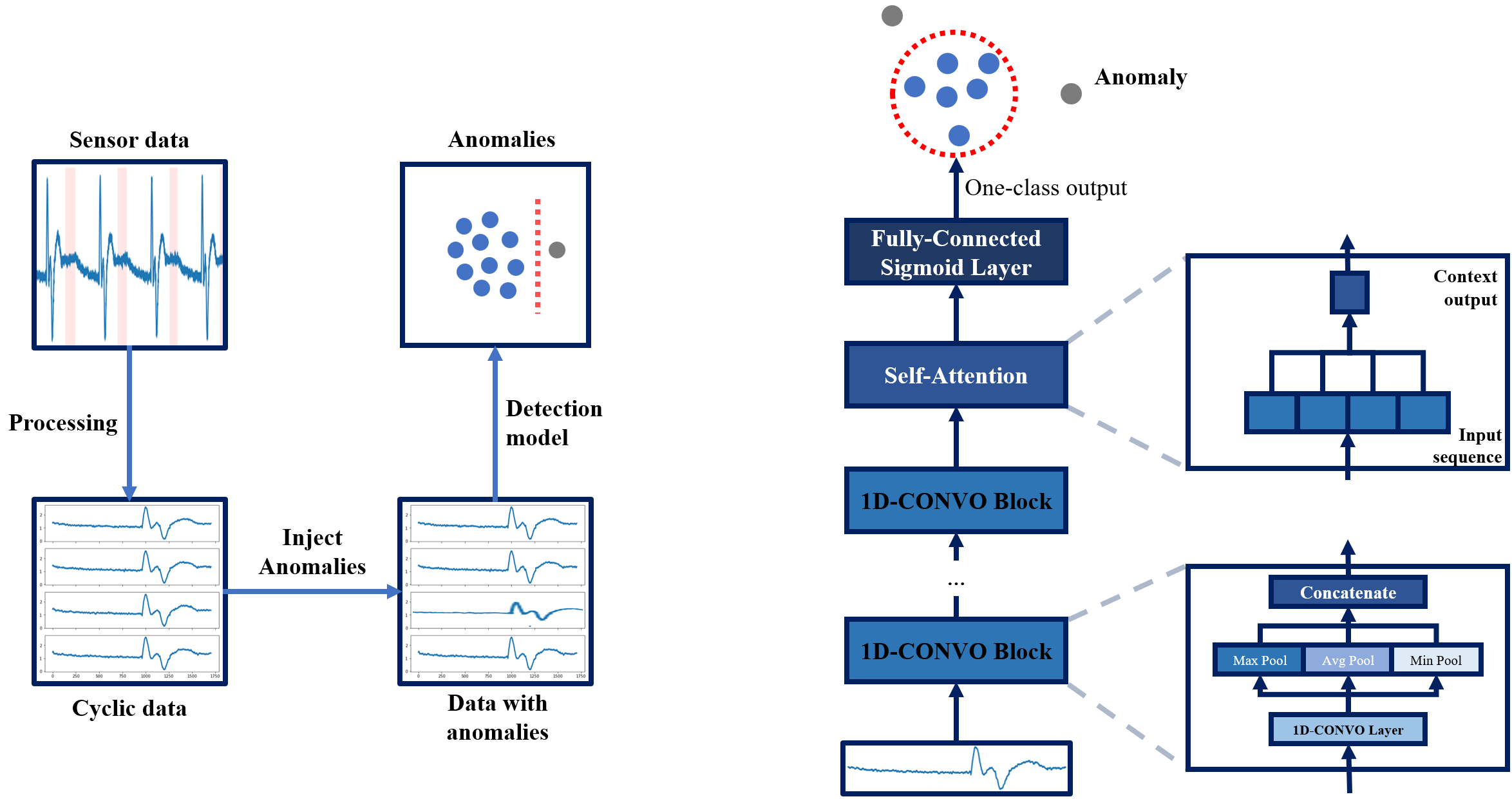
One-class Attention Architecture for Anomaly Detection in Manufacturing
This research was presented in IntelliSys 2021.
Motivation: Predictive Maintenance is an important in any manufacturing industries. In brief, this means to perform maintenance prior to the degradation of system's performance within a certain threshold and when the maintenance activity is the most cost-effective. The emergence of Industrial Internet of Things has provided us with more effective approaches to track the operation parameters of a manufacturing system using sensors. Data from sensors can provide valuable insights on the current health status of a system, and therefore, is the focus of this project.
Product: We developed emprical architectures to detect different types of irregularities in data collected from a manufacturing system in operations. Then, we performed in-depth evaluation of the new method vs. state-of-the-art anomaly detection models.
Technology: We focus on various types of sensors which measure air pressures, water pressures, temparatures, and positions and torques of a transportation motor, in a cyclical system. More specifically, the system works in a cyclic nature - the collected data can be divided into cycles with similar patterns, each of which form a data instance in this anomaly detection task. Since procuring labeled data with actual anomalies is costly, we simulate four types of abnormal patterns to examine the models' behaviors in each case. We empirically designed an rchitecture called One-Class Self-Attention (OCSA) model. OCSA integrates self-attention mechanisms with the one-class classifier training objective to incorporate the representation capacity of the former and the modeling capability of the latter.
Result: Our technology consistently achieve the highest or competitive performances in both detection rates and in running times compared to state-of-the-arts including One-Class Support Vector Machine, Isolation Forest, Deep Auto-Encoders, and Deep One-Class Classifier.
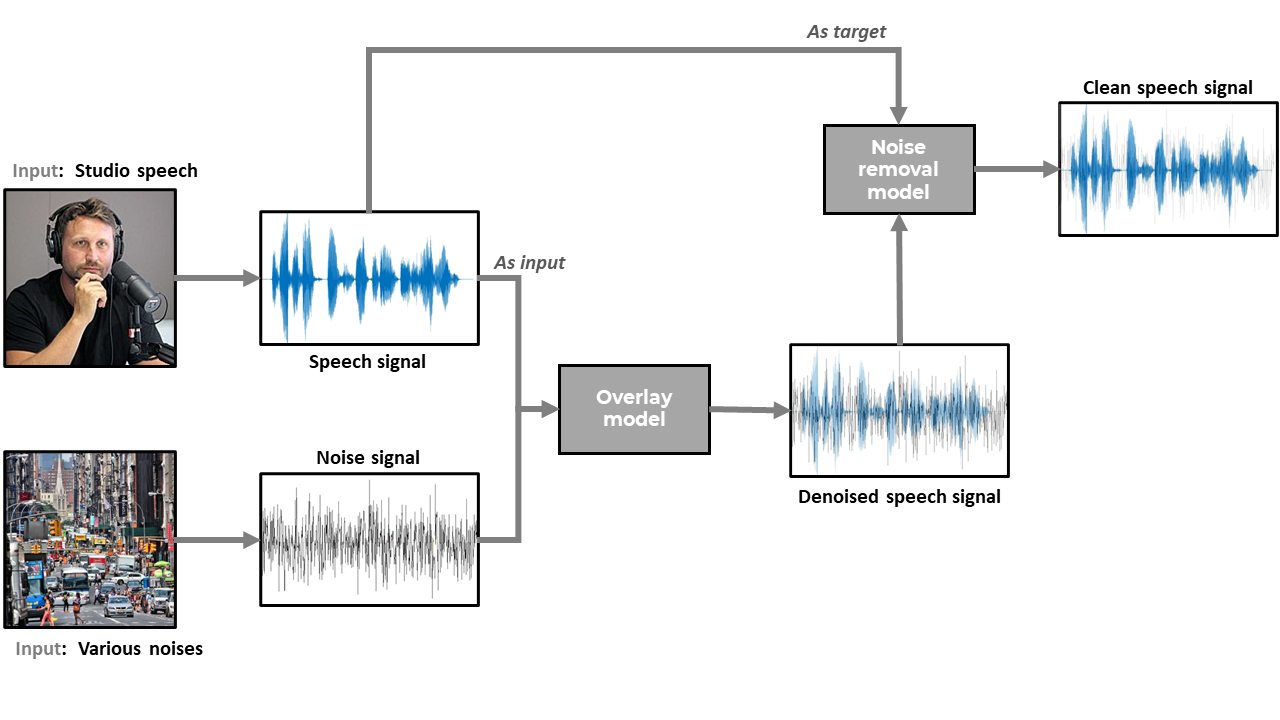
Environment Noise Removal for Speech Processing
This was a capstone project for two student teams that I mentored in 2020. The work from one team won KSU C-Day Spring 2020.
Motivation: Speech recognition technologies have numerous applications in many domains such as recording, teleconference, voice commands, etc. An obvious issue with any speech recognition models is the presence of environment noises which can distract them from the main contents. Therefore, this project aims to address the challenge of noise removal in audio data.
Technology: We explored different techniques on removing noises from speech data. We start with speech data collected in studio environment (i.e. can be considered noise free). We then overlay different types of noises onto the speech and try to recover the original signals from the denoised one. Tested techniques include machine learning and deep learning algorithms, as well as other traditional noise removal methods.
Result: We derived a LSTM-based sequence-to-sequence model that can recover the true voice signal at a standardized MAE of 0.07.
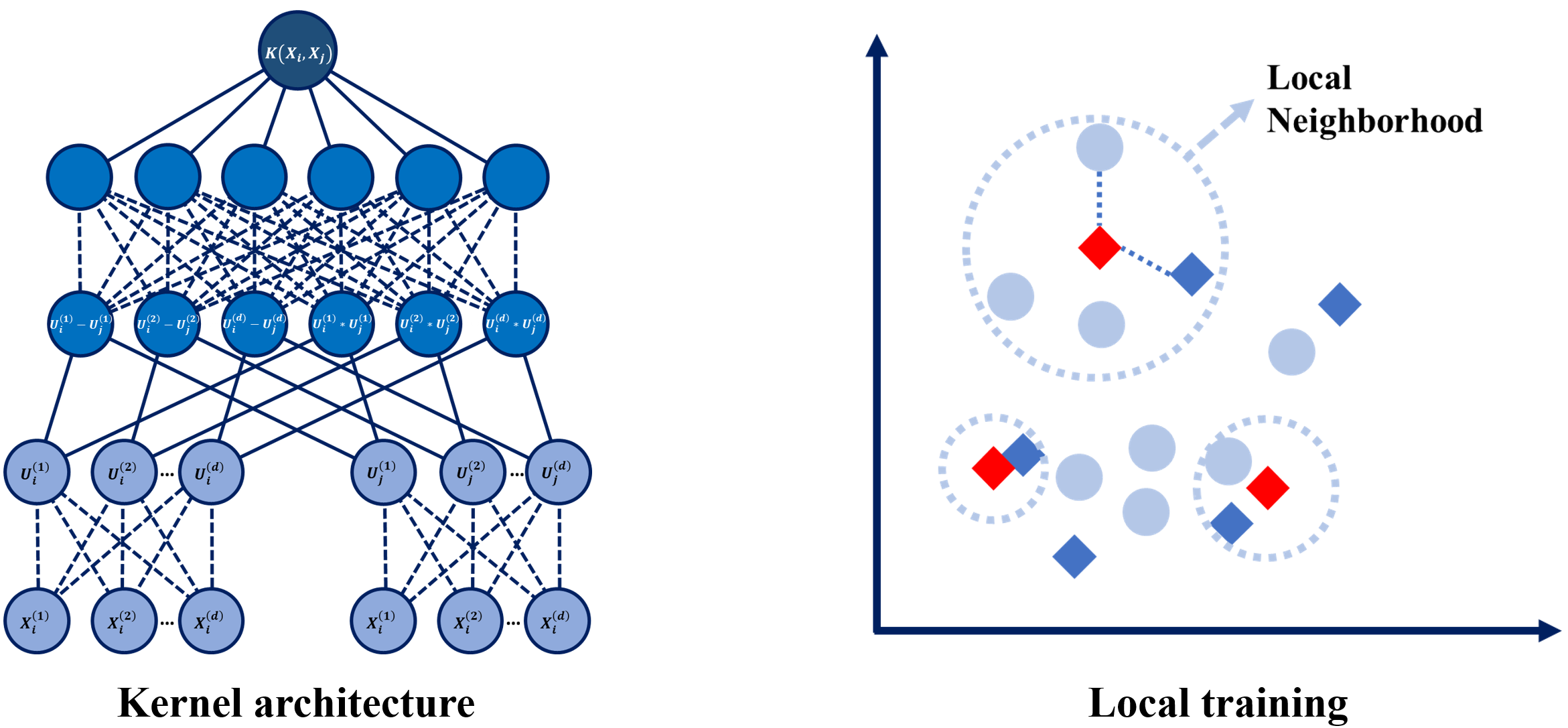
Deep Embedding Kernel
This project was the topic of my dissertation. Related works were published in IEEE Big Data 2018 and Neurocomputing 2019. This project is also the base for my patent issued in 2022.
Motivation: Kernel methods and deep learning are two major branches of machine learning with numerous successes in data analytics and artificial intelligence. Kernel methods have been widely used in pattern recognition; on the other hand, many deep learning models, such as AlexNet, Google Facenet, and ResNet, archived breakthrough performances when they were proposed. Both, however, have their own weakness. With that motivation, this project derive a new supervised model possesseing significant strengths of both methods, meanwhile remedies their significant weakness.
Product: We developed a novel supervised learning method that is called Deep Embedding Kernel (DEK) that combines the advantages of deep learning and kernel methods in a unified framework.
Technology: DEK is a learnable kernel represented by a newly designed deep architecture. Compared with predefined kernels, this kernel can be explicitly trained to map data to an optimized high-level feature space where data has favorable features toward the application. Compared with typical deep learning using SoftMax or logistic regression as the top layer, DEK is more generalizable to new data.
Result: DEK had superior performances than typical machine learning methods in identity detection and classification, and transfer learning, on different types of data including images, sequences, and regularly structured data.
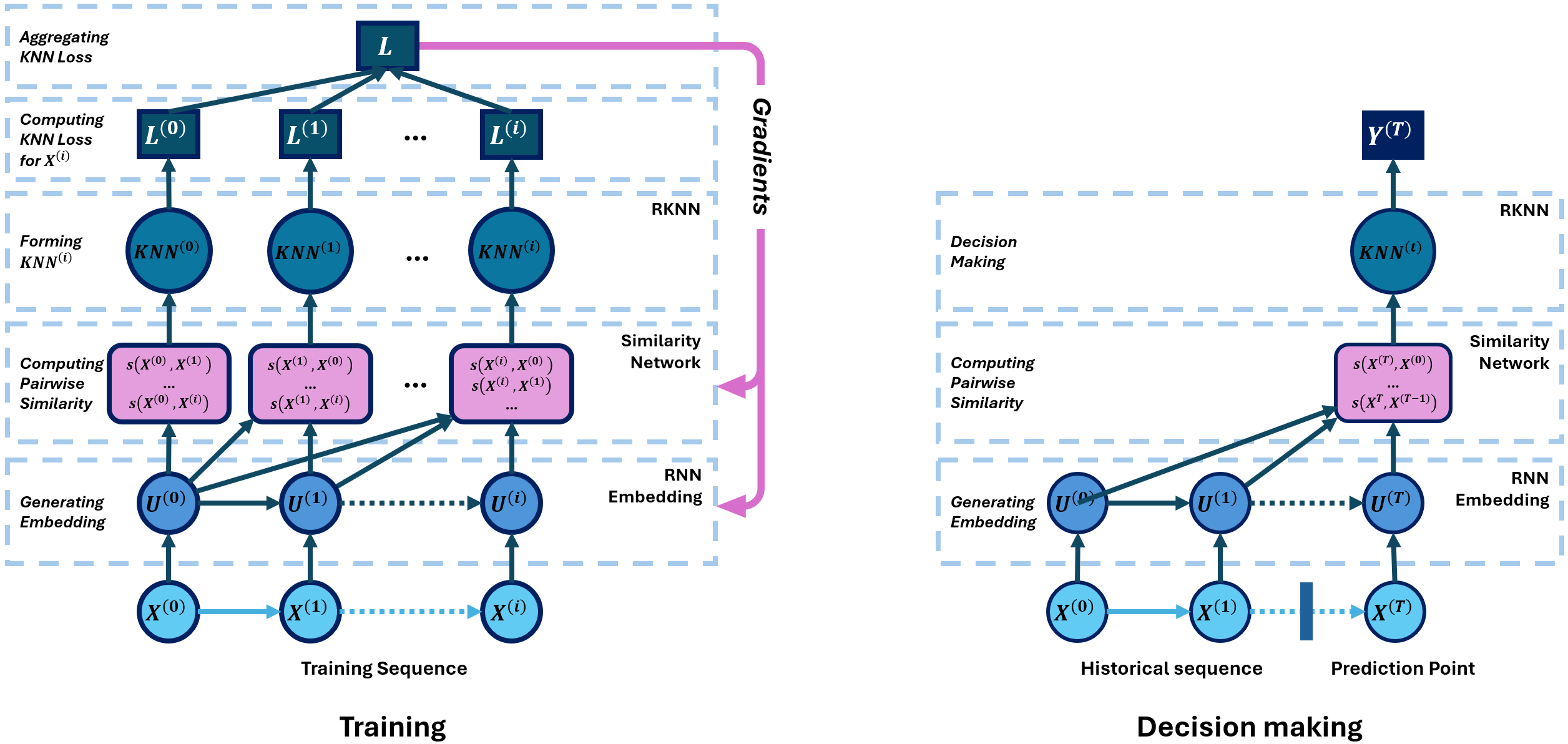
Recurrent KNN for Predicting Daily Stock Price Direction
This work was presented in IEEE/ACM International Conference on Big Data Computing Applications and Technologies (BDCAT) 2018.
Motivation: Stock price movement is typically affected by a lot of hidden factors. Predicting stock price direction, especially short-term direction, is very challenging and consistently attracts researches. Recent works have started to use deep recurrent neural networks, such as Long Short-Term Memory, in the task of modeling stock data. These deep models typically outperform statistical time series models and traditional machine learning approaches with their mechanisms of learning historical information. However, encoding entire history into a vector may unavoidably causes information loss regardless of memory learning and updating mechanisms. This project addresses the challenge of remembering long historical data with a a novel architecture.
Product: We developed a recurrent K-Nearest-Neighbors (RKNN) for supervised tasks on sequential data. Then, we apply the RKNN model on predicting daily stock price directions.
Technology: RKNN learns to make optimal decisions by referring to the entire history instead of just current memory vectors. Specifically, RKNN computes an embedding representation for each time point in the sequence using a RNN architecture. Then, the embeddings are input into a metric network to calculate their pairwise similarity. Finally, a KNN model is utilizied using the learned metrics to make decision.
Result: We tested RKNN on multiple stock ETFs with different long-term trends and showed that RKNN significantly outperforms RNN, LSTM, and GRU, on predicting daily price direction.
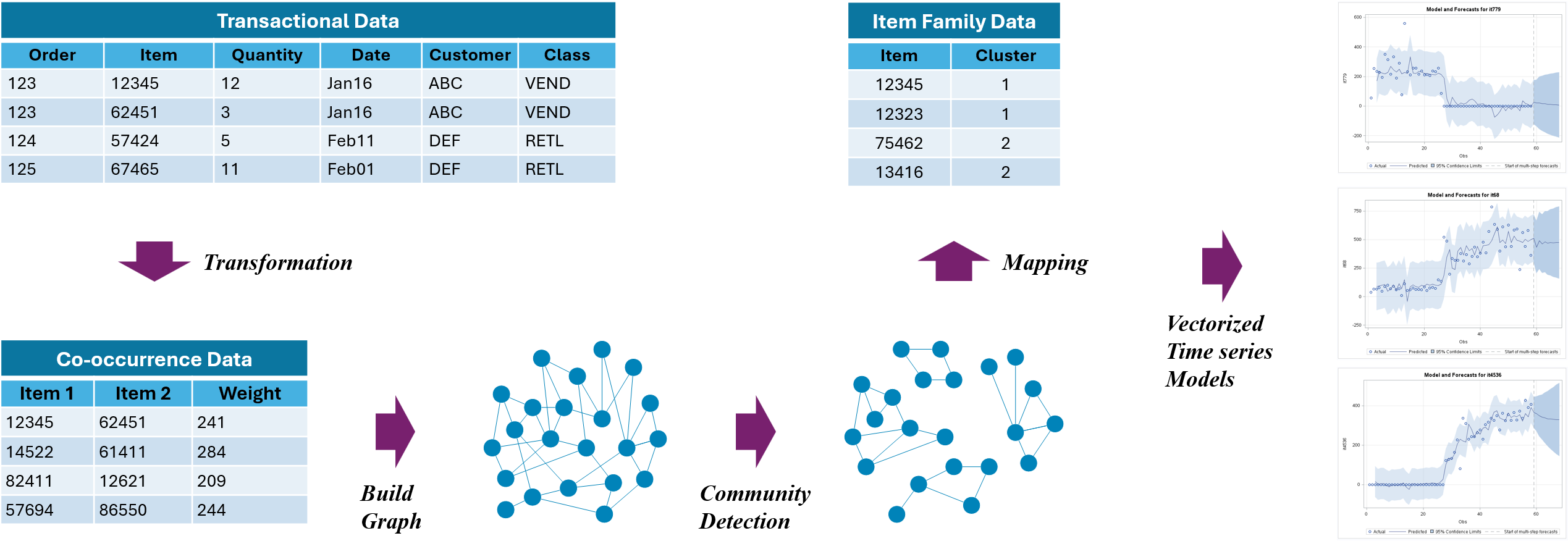
Graph-based Multivariate Sales Forecasting
This work was presented in SAS Global Forum 2017. An earlier version won best poster in SAS Analytics Experience 2016.
Motivation: Market-basket analysis and sales forecasting are two important tasks for any retailers. This project aims to incorporate these two business problems into one unified framework utilizing graph theory.
Product: We developed a graph-based approach to the market basket problem as well as further formulated vectorized multivariate forecasting models for product sales. Specifically, transactions from customers are evaluated to determine groups of items frequently purchased together, with the resulting groupings then used to forecast future sales.
Technology: The data is provided by a major supply chain company with over 42 million transactions in 250+ variables. The data has approximately 110,000 distinct item IDs across 2.35 million unique orders during 68 weeks. The original data is in the transactional format that normalizes the order-item relationship. For processing, data is first transformed into item co-occurrence format. The co-occurrence data is then used to buid a graph. Next, we perform community detection on the item graph to obtain clusters of items frequently purchased together. Finally, we apply vector autoregressive moving average models on sales series of items in the same clusters.
Result: We are able to reduce about 70% forecasting errors compared to regular ARIMA models.